Google BigQuery is a fully managed, cloud-native data warehousing solution that allows you to analyze large and complex datasets using SQL. It is designed to handle petabyte-scale datasets, and provides fast query performance through the use of columnar storage, in-memory caching, and other optimization techniques. Because it is fully managed, there is no need to set up or manage any infrastructure, which makes it easy to use and highly scalable.
One of the main benefits of using BigQuery is its speed and performance. It is designed to process queries over large datasets very quickly, making it suitable for a wide range of applications that require fast and accurate results. It does this by using a distributed architecture, where data is stored in multiple servers and processed in parallel, which allows it to handle a high volume of queries and users without any impact on performance.
BigQuery also offers a range of other capabilities, such as the ability to run SQL-like queries against data stored in other Google Cloud Platform products, such as Google Cloud Storage and Google Ads. Overall, BigQuery is a powerful and convenient tool for analyzing large and complex datasets in the cloud.
Google BigQuery Pricing Model
Google BigQuery offers two pricing models for storage and querying: Pay-per-use (on-demand) and flat-rate.
Pay-Per-Use
BigQuery’s pay-per-use pricing model charges you for the amount of data you store and the amount of data you query.
For storage, you are charged based on the amount of data you store in BigQuery, measured in gigabytes (GB). The cost of storing data in BigQuery is $0.02 per GB per month.
For querying data, you are charged based on the amount of data that is read by each query. This is measured in bytes, and the cost is $5 per terabyte (TB) of data read.
There are also charges for using the Storage API to load data into BigQuery or export data from BigQuery, as well as for using the Streaming API to insert data into BigQuery in real-time. The cost for these operations varies depending on the amount of data being transferred and the number of requests made.
Here are some examples to help illustrate how BigQuery’s pay-per-use pricing model works:
- If you store 100 GB of data in BigQuery and query 1 TB of data over the course of a month, your total cost would be $100 for the storage (100 GB x $0.02/GB) + $5 for the query (1 TB x $5/TB) = $105.
- If you use the Storage API to load 1 TB of data into BigQuery and then export 1 TB of data from BigQuery, your total cost would depend on the number of requests you make and the amount of data being transferred. For example, if you make 1,000 requests to load data and 1,000 requests to export data, and each request transfers 1 GB of data, your total cost would be 1,000 requests x $0.05/request for loading + 1,000 requests x $0.05/request for exporting = $100.
- If you use the Streaming API to insert 1 TB of data into BigQuery in real-time, your total cost would depend on the number of insert requests you make and the amount of data being transferred. For example, if you make 10,000 insert requests and each request transfers 1 MB of data, your total cost would be 10,000 requests x $0.01/request = $100.
Pay-Per-Use (On-Demand) vs Flat Rate
Under the on-demand pricing model, you pay for the amount of data you store in BigQuery, as well as the number of queries you run and the amount of data you stream into the platform. This model is designed for organizations that have varying workloads and don’t want to commit to a fixed amount of storage upfront.
Under the flat-rate pricing model, you can purchase a fixed amount of storage at a discounted price and pay a lower per-query rate for your queries. This model is best for organizations with predictable workloads that want to commit to a certain amount of storage upfront.
In Google BigQuery, storage is classified into two types.
- Active Storage – Storage used by tables or partitions that have been modified in the last 90 days.
- Long-term Storage – Storage used by tables or partitions that have not been modified in the last 90 days.
Confusing? It can be. Let us demystify this for you.
It is essential to understand this distinction because the amount you pay for Google BigQuery might vary significantly based on how your tables and partitions have been defined.
For example, consider a table with 10Gb of data with all the data stored in a single partition. When you insert a new row into this table, that new role gets created in the same partition rending the partition to be considered an active partition.
Assume that the table stated above has order data for the last 10 years. Daily, only data that got created in the last one month gets queried. In this case, breaking the partitions down by MON-RR of the order creation date creates a few smaller partitions. When a new record gets inserted, only the partition for the current MON-RR gets impacted. Breaking down the table using such logic would mean that only 3 or 4 smaller partitions are considered as active at any given time (remember the 90-day rule?) instead of the single large partition. As a result, the pricing for storage reduces because a majority of the partitions get billed under long-term storage, and some of them get billed under active storage.
It is important to note that the logic used for partitioning tables has to be chosen carefully after a thorough evaluation of the queries that are required to run.
Let’s dig one level deeper to understand how storage utilized is calculated by taking a simple example. Assume that you are creating a table, sample_table, with 2 columns and 10 rows.
- Column A – Integer
An integer field uses 8 bytes of storage - Column B – Numeric
An integer field uses 16 bytes of storage
For 10 rows inserted into the sample_table, the total storage utilized is:
(8 Bytes * 10) + (16 Bytes * 10) = 240 bytes
You get charged for 240 bytes. At the time of writing this article, Google doesn’t charge users for storage up to 10GB. So, this was the only table, you wouldn’t see a charge.
This pricing effectively means that a lot of small businesses can technically adopt a fully managed data warehouse without having to pay a hefty bill.
The table below lists the various data types that BigQuery supports and the storage utilized for each data type.
| Data type | Size |
| INT64/INTEGER | 8 bytes |
| FLOAT64/FLOAT | 8 bytes |
| NUMERIC | 16 bytes |
| BOOL/BOOLEAN | 1 byte |
| STRING | 2 bytes + the UTF-8 encoded string size |
| BYTES | 2 bytes + the number of bytes in the value |
| DATE | 8 bytes |
| DATETIME | 8 bytes |
| TIME | 8 bytes |
| TIMESTAMP | 8 bytes |
| STRUCT/RECORD | 0 bytes + the size of the contained fields |
| GEOGRAPHY | 16 bytes + 24 bytes * the number of vertices in the geography type (you can verify the number of vertices using the ST_NumPoints function) |
Please review the Google BigQuery pricing summary page to get the update to data information on the storage pricing.
For querying, BigQuery charges based on the amount of data processed by your queries. You can choose to pay for queries on an on-demand basis or use the flat-rate pricing model to get a discounted rate on queries. You can also use the BigQuery Reservations service to save money on queries by pre-purchasing query processing capacity.
For an accurate assessment of costs of storage, it is prudent to always rely on the official BigQuery pricing calculator.
Google BigQuery Architecture
Here are some key details about the architecture of BigQuery:
Processing Engines
- BigQuery uses a column-based storage format and a SQL-like query language to analyze data. It supports real-time querying of large datasets using a multi-version concurrency control (MVCC) architecture.
- BigQuery executes queries using a distributed computing model called Dremel, which is based on a tree architecture and is designed to process structured and semi-structured data at high speeds.
- BigQuery also has a separate engine called BigQuery ML, which allows users to create and execute machine learning models directly within the BigQuery environment using SQL.
Storage Options
- BigQuery stores data in a highly-scalable and durable manner using Google Cloud Storage, which is Google’s object storage service.
- BigQuery supports a variety of storage options, including standard storage (which is suitable for most workloads), cold storage (which is less expensive but has longer access latencies), and nearline storage (which is a balance between the two).
- BigQuery also has a feature called Federated Query, which allows users to query data that is stored in external systems (such as Google Sheets or Google Cloud Storage) as if it were stored directly in BigQuery.
To address the issues of petabyte-scale data storage, networking, and sub-second query response times, Google engineers invented new technologies, initially for internal use, that are code-named Colossus, Jupiter, and Dremel. The externalization of these technologies is called Google BigQuery.
Dremel
Dremel is the query execution engine that powers BigQuery. It is a highly scalable system designed to execute queries on petabyte-scale datasets. Dremel uses a combination of columnar data layouts and a tree architecture to process incoming query requests. This combination enables Dremel to process trillions of rows in just seconds. Unlike many database architectures, Dremel is capable of independently scaling compute nodes to meet the demands of even the most demanding queries.
Dremel is also the core technology that supports features of many Google services like Gmail and YouTube and is also used extensively by thousands of users at Google. Dremel relies on a cluster of computing resources that execute parallel jobs on a massive scale. Based on the incoming query, Dremel dynamically identifies the amount of computing resource needed to fulfill the request and pulls in those compute resources from a pool of available compute and processes the request. This extensive compute pooling happens under the covers, and the operation is fully transparent to the user issuing the query. From a user standpoint, they fire a query, and they get results in a predictable amount of time every time.
Colossus
Colossus is the distributed file system used by Google for many of its products. In every Google data center, google runs a cluster of storage discs that offer storage capability for its various services. Colossus ensures that no data loss of data stored in the discs by choosing appropriate replication and disaster recovery strategies.
Jupiter Network
Jupiter network is the bridge between the Colossus storage and the Dremel execution engine. The networking in Google’s data centers offers unprecedented levels of bi-directional traffic that allows large volumes of data movement between Dremel and Colossus.
Google combined these technologies and created an external service called BigQuery under the Google Cloud Platform. BigQuery is a cloud-native data warehouse that provides an excellent choice as a fully-managed data warehouse. BigQuery, with its de-coupled compute and storage architecture, offers exciting options for large and small companies alike.
Google BigQuery Pros and Cons
Let’s look at advantages and disadvantages of Google BigQuery and whether it’s the right choice for you:
10 Benefits of Using BigQuery for Data Analysis and Querying
- On the Go analytics – easy and fast: BigQuery allows you to quickly and easily analyze large amounts of data using SQL-like queries. This makes it possible to get insights from your data in real-time, without having to wait for data to be transferred or processed.
- Prerequisites are minimal: To use BigQuery, you don’t need any special hardware or software. All you need is an internet connection and a Google account.
- Infrastructure setup is not required: With BigQuery, you don’t need to worry about setting up and maintaining any infrastructure. Google manages all of the underlying infrastructure for you, so you can focus on analyzing your data.
- Data Storage and Transformation, Calculations are executed separately: BigQuery separates the process of storing and transforming data from the process of running calculations on it. This means you can store and transform your data without incurring additional processing costs.
- No redundant data storage: BigQuery allows you to store your data in a highly optimized, columnar format that reduces the amount of redundant data that is stored. This helps to reduce storage costs and speeds up query processing.
- Building and scaling tables are comfortable: BigQuery makes it easy to build and scale tables to handle even the largest datasets. You can scale up or down as needed, and you only pay for the storage and processing that you use.
- Access control at the project, dataset, and field level: BigQuery allows you to set fine-grained access controls at the project, dataset, and field level. This helps you to ensure that only authorized users can access your data. This is particularly important for organizations that need to comply with regulations such as HIPAA or GDPR.
- The most complex query fetching terabytes of data can be executed in seconds: BigQuery is designed to handle even the most complex queries that involve terabytes of data. It can execute these queries in just seconds, thanks to its powerful distributed architecture.
- More recommended service uptime since deployment is across the platform: BigQuery is deployed across Google’s infrastructure, which means it benefits from the same level of uptime as other Google services. This makes it a reliable choice for mission-critical applications.
- Integration with other Google Cloud services: BigQuery integrates seamlessly with other Google Cloud services, such as Google Cloud Storage, Google Sheets, and Google Cloud Data Studio, allowing users to easily perform data analysis and visualization.
8 Potential Drawbacks of Using BigQuery
- Limited customizability: Because BigQuery is a fully-managed service, users do not have full control over the underlying infrastructure and may be limited in terms of customizing the system to their specific needs.
- Limited support for certain data types: BigQuery does not support data types such as arrays, maps, or structs, which can be limiting for certain types of data analysis.
- Difficulty with unstructured data: BigQuery is optimized for structured and semi-structured data, and may not be the best choice for analyzing unstructured data.
- Workflow is complicated for a new user: Some users may find the workflow for using BigQuery to be complicated, especially if they are not familiar with SQL or data analysis. It can take some time to learn how to use the tool effectively.
- Modify/Update Delete – not supported by Google BigQuery: BigQuery does not support the ability to modify or delete individual rows in a table. If you need to make changes to your data, you will need to overwrite the entire table or use a series of INSERT, UPDATE, and DELETE statements.
- Issues occur when serial operations are in scope: BigQuery is optimized for running large, parallel queries across many CPU cores. This means it may not perform well when running a large number of serial operations.
- There is a daily destination table update limit set as 1,000 updates per table per day: By default, BigQuery limits the number of times that you can update a destination table to 1,000 updates per day. If you need to update a destination table more frequently than this, you may need to request an increase to your quotas.
- There are a few more limitations such as concurrent queries, max run time, etc. set by default: BigQuery has a number of default limitations in place to ensure that it can run efficiently and fairly for all users. These limitations include the number of concurrent queries that you can run, the maximum run time for a query, and the amount of data that you can scan per day. If you need to exceed these limitations, you may need to request an increase to your quotas.
Also, read:
Getting Started with BigQuery
Creating a BigQuery Project
To create a BigQuery project, you will need a Google Cloud account. Here are the steps you can follow to create a BigQuery project:
- Go to the Google Cloud Console.
- Click the project drop-down menu at the top of the page, and then click “Create project”.
- In the “New Project” window, enter a name for your project and select a billing account.
- Click “Create”.
Your new project will be created and will appear in the project drop-down menu. You can now enable the BigQuery API for your project by clicking the “APIs & Services” button in the Cloud Console and searching for “BigQuery API”. Click on the API and then click “Enable” to enable it for your project.
Once the BigQuery API is enabled, you can create a BigQuery dataset and start running queries. You can use the BigQuery web UI, the BigQuery command-line tool, or the BigQuery API to interact with BigQuery.
Loading Data into a Dataset
To continue using BigQuery, you will need to load your data into a BigQuery dataset. There are several ways to do this:
- Streaming inserts: You can stream data into BigQuery in real-time using the tabledata().insertAll method of the BigQuery API. This is a good option if you want to ingest data in real-time and don’t have a lot of data to load.
- Batch imports: You can use the bq command-line tool or the load method of the BigQuery API to load data from a file in Cloud Storage or from a local file. This is a good option if you have a large amount of data to load and don’t need it to be available in real-time.
- Exporting data from another service: You can use the export method of the BigQuery API to export data from another service, such as Google Analytics, into a BigQuery dataset.
Once your data is loaded into a BigQuery dataset, you can use SQL-like queries to analyze it. You can use the BigQuery web UI, the bq command-line tool, or the query method of the BigQuery API to run queries.
Running Queries on BigQuery using Familiar SQL-like Syntax
BigQuery uses a SQL-like syntax for querying data. If you are familiar with SQL, you should find it easy to write queries in BigQuery. Here is a simple example of a SELECT query that retrieves all rows from a table:
SELECT * FROM `my-project.my_dataset.my_table`;
You can also use WHERE clauses, GROUP BY clauses, and other SQL statements to filter and aggregate your data. For example, the following query counts the number of rows in a table by grouping them by a specific column:
SELECT COUNT(*) as num_rows, col1 FROM `my-project.my_dataset.my_table` GROUP BY col1;
BigQuery also has some advanced features that are not available in standard SQL, such as support for semi-structured data (e.g. JSON), support for geographic data types, and the ability to query data stored in Cloud Storage.
If you are new to BigQuery and SQL, you may find it helpful to refer to the BigQuery documentation or take a look at some sample queries to get started.
In-Depth Guide to BigQuery
Let’s look at the important aspects and few advanced features in Google BigQuery:
Loading and Exporting Data
- There are several ways to load data into BigQuery:
- Streaming inserts: You can use the INSERT API to insert rows one at a time using HTTP requests. This is useful for real-time data ingestion.
- Batch loading: You can use the LOAD API to load data from a file stored in Google Cloud Storage. This is the most common way to load data into BigQuery and is suitable for batch ingestion.
- File uploads: You can use the BigQuery web UI or the bq command-line tool to upload a file from your local machine. This is suitable for small datasets.
- To export data from BigQuery, you can use the EXPORT API to export a table or query results to a file in Google Cloud Storage. You can then download the file to your local machine or use it as input for another tool.
Querying Data
- You can use SQL to query data in BigQuery. BigQuery supports a subset of ANSI SQL and also includes some additional features and functions.
- To run a query, you can use the BigQuery web UI, the bq command-line tool, or the jobs.query() method in the BigQuery API.
- You can also save query results to a new table, update an existing table with the results, or create a view based on the results.
Using the BigQuery API
- The BigQuery API allows you to programmatically access BigQuery data and functionality. You can use it to create, update, and delete datasets and tables, run queries, and export data.
- To use the BigQuery API, you will need to enable the API for your project and set up authentication. You can use a service account or OAuth 2.0 to authenticate your API requests.
- The API uses RESTful calls and responses are in JSON format. You can use the API with a variety of programming languages, including Python, Java, and Node.js
Query Parameters and Templates
- Query parameters allow you to use a single query template with multiple sets of input values.
- You can define query parameters by using the @ symbol followed by the parameter name. For example:

- You can then use the bq command-line tool or the jobs.query() method in the BigQuery API to specify the input values for the query parameters when you execute the query.
- Query templates are useful for creating reusable queries that accept input from the user or a script.
Query Optimization
There are several strategies you can use to optimize your queries in BigQuery:
- Use the EXPLAIN keyword to see how BigQuery is executing your query. This can help you understand why a query is slow and identify areas for optimization.
- Use columnar data formats, such as Parquet or ORC, which are optimized for fast querying. BigQuery can natively read these formats, so you don’t need to load the data into another format before querying it.
- Use partitioned tables to restrict the amount of data that is scanned by a query. Partitioned tables are divided into smaller segments called partitions, which can be queried independently. By specifying a WHERE clause that filters on the partitioning column, you can restrict the amount of data that is scanned by a query.
- Use clustering to physically order the data in your table based on the values in one or more columns. This can speed up queries that filter or group by these columns, since the data is already sorted.
Partitioned Tables
- Partitioned tables allow you to store and query large datasets more efficiently by dividing the data into smaller partitions. Each partition contains a subset of the data for a specific time or date range.
- Partitioned tables are especially useful for tables with a large number of rows that are frequently queried over a specific time range, such as a daily table with billions of rows.
- To create a partitioned table, you need to specify a partitioning column and its data type when you create the table. The partitioning column must be a TIMESTAMP or DATE column.
- You can use the CREATE TABLE or CREATE TABLE AS SELECT (CTAS) statements to create a partitioned table.
Table Wildcard Functions
- Table wildcard functions allow you to query multiple tables or views using a single SQL statement.
- The * wildcard function returns all rows in all tables or views that match a specific pattern. The _ wildcard function matches any single character in the table or view name.
- For example, you can use the following statement to query all tables that start with “events_” in a specific dataset:

- Table wildcard functions are useful for querying tables that are generated by a job or script and have a consistent naming pattern.
Machine Learning
BigQuery has built-in machine learning capabilities that allow you to build and deploy machine learning models directly from your BigQuery dataset. You can use SQL to create and train models, and then use the MODEL_EVALUATE function to evaluate the performance of your model. BigQuery also integrates with other Google Cloud machine learning products, such as TensorFlow, so you can build more complex models and use them to make predictions on your BigQuery data.
Here are a few examples of how you can use machine learning in BigQuery:
- Use the ML.TRAINING_INFO function to get information about a model, such as the training loss and accuracy.
- Use the ML.PREDICT function to make predictions using a trained model. You can pass in input data and the function will return the predicted output.
- Use the ML.EVALUATE function to evaluate the performance of a trained model. You can pass in input data and the corresponding expected output, and the function will return metrics such as accuracy and AUC.
Real-Time Streaming Inserts
BigQuery supports streaming data inserts, which allows you to stream data into a BigQuery table in real-time. This is a good option if you want to ingest data as it becomes available and don’t have a lot of data to load.
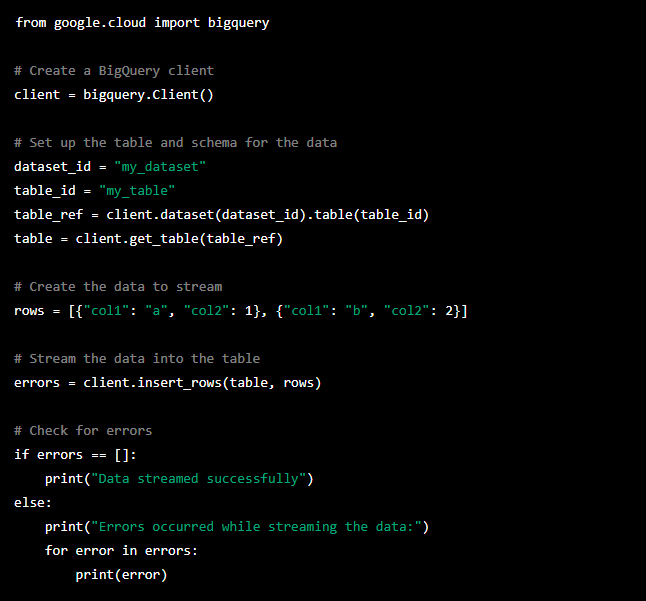
To stream data into BigQuery, you can use the tabledata().insertAll method of the BigQuery API. This method accepts a request body containing a list of rows to insert, along with other options such as the table to insert the rows into. You can then use the API to send data to BigQuery as it becomes available.
Here is an example of how you can use the tabledata().insertAll method in the Python API client:
Geospatial Data Types
BigQuery supports geospatial data types, which you can use to represent geographic data in your tables. There are two geospatial data types in BigQuery:
- POINT: Represents a single point on the Earth’s surface.
- GEOGRAPHY: Represents a geometry, such as a polygon or a line, defined on the Earth’s surface.
You can use geospatial functions, such as ST_DISTANCE, to analyze and query this data. For example, you can use the ST_DISTANCE function to calculate the distance between two points on the Earth’s surface.
Here is an example of how you can use the ST_DISTANCE function in a BigQuery query:

Semi-Structured Data Types
BigQuery supports data types for storing and querying semi-structured data, such as JSON and Avro. This makes it easy to work with data that has a flexible structure, such as data from web logs or data from IoT devices.
Semi-structured data types refer to data stored in a format that is not a traditional tabular structure with rows and columns, but still contains structured elements such as tags and metadata. BigQuery supports several types of semi-structured data, including:
- JSON: a lightweight data interchange format that is easy for humans to read and write and easy for machines to parse and generate.
- Avro: a row-based binary data serialization format that is easy to process with a variety of programming languages.
- Parquet: a columnar storage format that is highly efficient for storing and querying large datasets.
To store semi-structured data in BigQuery, you can use the RECORD data type. This data type allows you to define a nested structure for your data, with each field having its own data type. You can then use the -> operator to access fields within the record.
There are two semi-structured data types in BigQuery:
- RECORD: This data type represents a set of named fields, each with its own data type. The fields can be of any data type, including other RECORDs. Here is an example of how you might use the RECORD data type:

- ARRAY: This data type represents a list of elements, all of the same data type. You can use the ARRAY data type to store repeated data, such as a list of phone numbers for a contact. Here is an example of how you might use the ARRAY data type:

You can also nest ARRAYs and RECORDs to create complex data structures. For example:
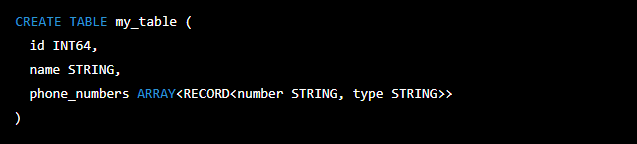
This table would have a field called phone_numbers that is an array of records, each of which has two fields: number (a string) and type (a string).
Data Transfer Service
Google BigQuery Data Transfer Service is a fully managed service that enables you to automate loading data from external data sources into BigQuery. With Data Transfer Service, you can load data from popular cloud storage providers such as Google Cloud Storage, Amazon S3, and Microsoft Azure Blob Storage, as well as from on-premises data sources such as FTP servers and Oracle databases.
The BigQuery Data Transfer Service allows you to schedule recurring imports of data from external sources, such as Google Ads and Google Analytics, into BigQuery. This can save you time and effort by automating the data import process.
You can also use it to move data between BigQuery projects and locations, allowing you to easily share data across teams and use cases.
To use Data Transfer Service, you will need to set up a transfer configuration that specifies the source and destination of the data, as well as any transformation or filtering rules that should be applied to the data. Once the transfer configuration is set up, you can create a transfer job to start the data load process. Data Transfer Service will handle all of the underlying infrastructure and data transfer logistics, allowing you to focus on analyzing your data rather than worrying about how to get it into BigQuery.
BigQuery ETL
In the context of BigQuery, ETL refers to the process of extracting data from external data sources, transforming the data to match the target data warehouse schema, and then loading the transformed data into BigQuery for analysis and reporting.
There are several ways to perform ETL in BigQuery:
- Use the BigQuery web UI to load data from files stored in Google Cloud Storage or from a streaming source.
- Use the BigQuery command-line tool or client libraries to load data from files stored in Google Cloud Storage or from a streaming source.
- Use third-party ETL tools, such as Daton, to extract data from various data sources and load it into BigQuery.
- Use Cloud Functions or Cloud Composer to build custom ETL pipelines that extract data from various sources and load it into BigQuery.
Overview of Using BigQuery for ETL Processes
Here is an overview of using BigQuery for ETL processes:
- Identify the data sources that you want to extract data from. These can be files stored in Google Cloud Storage, databases hosted on Cloud SQL or Cloud Bigtable, or other cloud storage systems such as Amazon S3 or Azure Blob Storage or sources like Google Analytics, Facebook Ads, CRM, etc.
Common data sources for an eCommerce business, for example:Category
Tools
Analytics
Google Analytics, Mixpanel, Snowplow, Heap Analytics
Advertising
Facebook Ads, Google Ads, Pinterest, Taboola, Outbrain
Marketplaces
Amazon, Lazada, Walmart, Flipkart
Email Marketing Platforms
Klaviyo, MailChimp, Sendgrid, Constant Contact
Shopping Platforms
Shopify, BigCommerce, Magento, WooCommerce
Customer Support and Engagement
Intercom, Freshdesk, Freshchat, Zendesk
ERP Systems
Quickbooks, Xero, NetSuite
Databases
Oracle, SQL Server, MySQL, IBM DB2, Mongo DB, etc.
Files
Google Sheets, Excel, CSV, JSON, Parquet, XML etc
CRM
Hubspot, Salesforce, Freshsales, Pipedrive
Also, read:
- Determine the data schema of the source data. This will help you design the target data schema in BigQuery and map the source data fields to the corresponding target fields.
- Create a target table in BigQuery to hold the extracted and transformed data. You can do this using the BigQuery web UI, the command-line tool, or the client libraries.
- Extract the data from the source systems using one of the methods described above (web UI, command-line tool, client libraries, or third-party ETL tools).
- Transform the data as needed to match the target table schema. This may involve applying transformations such as data type conversion, field renaming, and data cleansing.
- Load the transformed data into the target table in BigQuery using the appropriate method (web UI, command-line tool, client libraries, or third-party ETL tools).
10 Tips and Best Practices for Using BigQuery for ETL
- Use Cloud Storage as a staging area for data files before loading them into BigQuery. This can make it easier to track the status of your ETL jobs and troubleshoot any issues that arise.
- Use partitioned tables to optimize the performance of your ETL jobs. Partitioning your data can help reduce the amount of data that is scanned and processed, which can lead to faster query performance and lower costs.
- Use query parameters to make your ETL jobs more flexible and reusable. This can be especially useful if you need to run the same ETL job with different parameters on a regular basis.
- Use Cloud Functions or Cloud Composer to automate your ETL processes. This can help ensure that your data is loaded into BigQuery on a regular basis and that any issues with the ETL process are automatically handled.
- Monitor the performance of your ETL jobs using Stackdriver Monitoring and the BigQuery web UI. This can help you identify bottlenecks in your ETL process and optimize your jobs for better performance.
- Use the BigQuery data transfer service to load data from external sources into BigQuery automatically on a scheduled basis. This can help ensure that your data is up-to-date and that your ETL jobs are running smoothly.
- Use the BigQuery export service to export data from BigQuery to other storage systems such as Cloud Storage or Cloud Bigtable. This can be useful if you need to use the data for other purposes or if you want to back up your data.
- Use Cloud Data Fusion to build and manage complex ETL pipelines with ease. Cloud Data Fusion is a fully managed, cloud-native data integration platform that allows you to create, schedule, and orchestrate data pipelines with a visual interface.
- Use Cloud Dataproc to perform data transformations and data cleansing at scale. Cloud Dataproc is a fully managed, cloud-native Apache Hadoop and Apache Spark service that can be used to process large amounts of data efficiently.
- Use Cloud Pub/Sub to stream data into BigQuery in real-time. Cloud Pub/Sub is a fully managed, cloud-native messaging service that can be used to ingest data from various sources and load it into BigQuery in near real-time.
Overview of Using BigQuery for Real-time Analytics on Big Data
To use BigQuery for real-time analytics, you will need to set up a streaming pipeline that ingests data into BigQuery in real-time. This can be done using Cloud Pub/Sub, which is a fully managed, cloud-native messaging service that allows you to publish and subscribe to streams of data.
Steps involved in setting up a streaming pipeline using Cloud Pub/Sub and BigQuery
- Identify the data sources that you want to stream data from. These can be databases, log files, IoT devices, or any other systems that generate data in real-time.
- Set up a Cloud Pub/Sub topic and subscription for each data source. A topic represents a stream of data, and a subscription represents a specific consumer of that data.
- Write code to publish data to the Cloud Pub/Sub topic(s) as it becomes available. This can be done using the Cloud Pub/Sub API or one of the available client libraries.
- Write code to consume data from the Cloud Pub/Sub subscription(s) and load it into BigQuery. This can be done using the BigQuery API or one of the available client libraries.
- Set up a Cloud Function or Cloud Composer workflow to orchestrate the streaming pipeline. This can help ensure that the pipeline is running smoothly and that any issues are automatically handled.
- Monitor the performance of the pipeline using Stackdriver Monitoring and the BigQuery web UI. This can help you identify bottlenecks in the pipeline and optimize it for better performance.
Once the streaming pipeline is set up, you can use SQL queries to analyze the data in BigQuery in real-time. You can use the BigQuery web UI, the command-line tool, or the client libraries to run queries and visualize the results.
9 Things to Keep in Mind when Using BigQuery for Real-Time Analytics
- Data that is streamed into BigQuery is not immediately available for querying. There is typically a delay of a few minutes between the time data is ingested and the time it is available for querying.
- BigQuery charges for both data ingestion and data storage. Be sure to monitor your usage and optimize your pipeline to minimize costs.
- The performance of real-time queries in BigQuery may be affected by the volume of data being ingested. If you are ingesting a very large volume of data, you may need to use partitioned tables and/or clustering to optimize query performance.
- Consider using Cloud Data Fusion or Cloud Dataproc to perform data transformations and data cleansing on the data before it is loaded into BigQuery. This can help reduce the complexity of your queries and improve query performance.
- Use Cloud Functions to trigger actions based on real-time data in BigQuery. For example, you can use Cloud Functions to send notifications or to update other systems in real-time based on the data in your BigQuery tables.
- Use Cloud Data Loss Prevention (DLP) to automatically detect and redact sensitive data in real-time as it is streamed into BigQuery. This can help ensure that you are compliant with data privacy regulations and that you are not accidentally exposing sensitive data.
- Use Cloud Memorystore for Redis to store and retrieve real-time data in a cache. This can help reduce the load on BigQuery and improve the performance of real-time queries.
- Use Cloud Bigtable to store and analyze real-time data at very high scale. Cloud Bigtable is a fully managed, cloud-native NoSQL database that is designed to handle extremely large volumes of data with low latency.
- Consider using a data warehousing solution other than BigQuery for real-time analytics if your use case requires very low latency (e.g. sub-second) or if you need to support a large number of concurrent real-time queries.
Solutions to 13 Common Problems while Working with BigQuery
13 recipes for common problems you might encounter when working with BigQuery:
- Loading data into BigQuery:
- If you want to load a CSV file from Cloud Storage into a BigQuery table, you can use the bq load command:
bq load –source_format=CSV mydataset.mytable gs://mybucket/myfile.csv myschema.json - If you want to load data from a local file, you can use the bq load command with the –noreplace flag to prevent overwriting an existing table:
bq load –source_format=CSV –noreplace mydataset.mytable myfile.csv myschema.json
- If you want to load a CSV file from Cloud Storage into a BigQuery table, you can use the bq load command:
- Exporting data from BigQuery:
- If you want to export a BigQuery table to a CSV file in Cloud Storage, you can use the bq extract command:
bq extract –destination_format=CSV mydataset.mytable gs://mybucket/myfile.csv - If you want to export a query result to a CSV file in Cloud Storage, you can use the bq query command with the –destination_format flag:
bq query –destination_format=CSV ‘SELECT * FROM mydataset.mytable’ > gs://mybucket/myfile.csv
- If you want to export a BigQuery table to a CSV file in Cloud Storage, you can use the bq extract command:
- Querying data in BigQuery:
- If you want to query all columns in a table, you can use the *wildcard:
SELECT * FROM mydataset.mytable - If you want to query only certain columns, you can specify the column names separated by commas:
SELECT col1, col2, col3 FROM mydataset.mytable - If you want to filter rows using a WHERE clause, you can use a condition to specify the rows you want to include:
SELECT * FROM mydataset.mytable WHERE col1 = ‘value’
- If you want to query all columns in a table, you can use the *wildcard:
- Optimizing performance:
If you want to improve the performance of a query, you can use the following tips:- Use a filter clause to eliminate unnecessary rows.
- Use a LIMIT clause to limit the number of rows returned.
- Use column aliases to reduce the amount of data that needs to be returned.
- Use a wildcard (*) instead of listing all column names.
- Querying large tables: To speed up queries on large tables, you can use partitioning and clustering. Partitioning divides the table into smaller, more manageable pieces based on a timestamp column or other integer column, while clustering organizes the rows within each partition based on the values of one or more columns.
- Handling null values: You can use the IFNULL function to replace null values with a default value in your query. For example:

- Dealing with nested and repeated fields: You can use the FLATTEN function to expand repeated fields into a single row. For example:

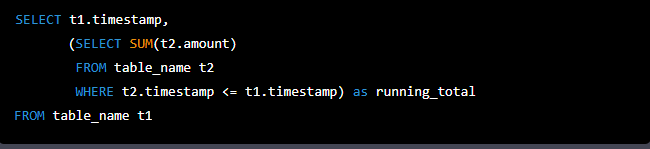
- Generating a running total: You can use the SUM function with a subquery to generate a running total. For example:
- Using window functions: You can use window functions to perform calculations across a set of rows. For example, you can use the RANK function to rank rows within a result set:

- Performing advanced analytics: You can use BigQuery’s built-in machine learning functions to perform advanced analytics on your data. For example, you can use the ML.LINEAR_REG function to perform linear regression:

- Performing a full outer join: You can use the FULL OUTER JOIN syntax to perform a full outer join in BigQuery. This will return all rows from both tables, filling in NULL values for any missing columns. For example:

- Pivoting rows to columns: You can use the pivot operator to pivot rows to columns. This can be useful for generating reports or summary tables. For example:

- Generating a histogram: You can use the HISTOGRAM function to generate a histogram of your data. This can be useful for visualizing the distribution of values within a column. For example:

Conclusion
In conclusion, BigQuery is a powerful and reliable data warehouse that can serve as the central hub for all of an organization’s data. If you are looking to take control of your data and unlock its full potential, then look no further than BigQuery and Saras Analytics. Our team of experts can help you set up a data warehouse, including BigQuery, and integrate all of your data sources. We can also build custom reports and perform advanced analytics to help you make informed, data-driven decisions. Don’t wait any longer to transform your data into actionable insights. Contact Saras Analytics today and take the first step towards a brighter future for your organization.