Over the past few years, a new design pattern has emerged among business data movement systems for data analytics. ELT (Extract-Load-Transform) is a new pattern that complements the classic ETL (Extract-Transform-Load) design technique. This article will outline the fundamental distinctions between ETL and ELT. You are not required to utilize a single design pattern for your approach, but you can declare one as the preferred design pattern for your architecture principles. Learn which option to use based on your needs by reading further.
What is Extract, Transform, and Load (ETL)?
ETL is a data integration approach that collects raw data from sources, transforms the data on a different processing server, and then loads the transformed data into a target database. When data must be changed to correspond to the data regime of the destination database, ETL is utilized. The approach was developed in the 1970s and continues to be utilized by on-premises databases with limited memory and computing capability.
Consider a working example of ETL. Data warehouses for Online Analytical Processing (OLAP) only accept relational SQL-based data formats. A technique such as ETL maintains compliance in this type of data warehouse by sending extracted data to a processing server and then transforming non-conforming data into SQL-based data. The extracted data is not sent from the processing server to the data warehouse until it has been converted successfully.
What is ELT (Extract, Load, Transform)?
Extract, load, and transform (ELT) does not require data transformations prior to the loading phase, unlike ETL. ELT inserts unprocessed data directly into a target data warehouse, rather than transferring it to a server for transformation. With ELT, data purification, enrichment, and transformation all take place within the data warehouse. The data warehouse stores raw data indefinitely, allowing for various transformations.
The emergence of scalable cloud-based data warehousing has made ELT a comparatively recent innovation. Cloud data warehouses, such as Snowflake, Amazon Redshift, Google BigQuery, and Microsoft Azure, all offer the storage and processing capability to support raw data repositories and in-app transformations. Although ELT is not utilized, it is gaining popularity as more businesses use cloud infrastructure.
Brief Overview of ETL and ELT Processes
Today, all types of businesses require data integration to organize, access and activate data within their organizations. To create outcomes in the data-driven economy, businesses must utilize dozens or hundreds of diverse data sources across nations, continents, and teams. In this complicated, fragmented environment, integrating different data sources into a cohesive perspective has never been more crucial. However, this difficulty is not new. Since the start of the digital era, data integration has plagued businesses.
The first technologies of the contemporary computer age laid the framework for data integration’s exclusive role. In the late 1960s, disk storage replaced punch cards, allowing for immediate data access. IBM and other firms pioneered the first Database Management Systems not long after (DBMS). These developments quickly facilitated the exchange of data between computers. The laborious procedure of merging data and data sources with external equipment became a problem very quickly.
In the 1970s, ETL evolved as the first common approach for simplifying data integration. ETL gained popularity when enterprise organizations implemented multifaceted computer systems and diverse data sources. These companies required a method to consolidate and centralize data from transactions, payroll systems, inventory records, and other enterprise resource planning (ERP) data.
In the 1980s, the proliferation of data warehouses made ETL even more crucial. Data warehouses could combine data from several sources, but specialized ETLs were often required for each data source. This resulted in a proliferation of ETL tools. By the end of the 1990s, many of these solutions were finally inexpensive and scalable for mid-market organizations as well as huge corporations.
With the advent of cloud computing in the 2000s, cloud data lakes and data warehouses led to the creation of ELT. With ELT, enterprises may directly load infinite raw data into a cloud-based DWH. On top of this raw data, engineers and analysts could conduct a limitless number of SQL queries directly within the cloud data warehouse. Big data has long promised that firms could access the analytical firepower and efficiency it offers. In conjunction with cloud DWHs and visualization tools, ELTs ushered in a new era of analytics and data-driven decision-making.
When Should You Transform Your Data
You should begin by examining the data types you will be dealing with. In many instances, evaluating the following variables can help you decide.
Data Format
If your data is unstructured, it does not cleanly fit into a relational framework, which is the basis for most analytics tools. In this situation, you will need to apply ETL to transform the data into a relational format that can be consumed by the end-user data consumers. If your data is already in a relational or flat format, it may be imported immediately ELT-style into the target, along with any sort/aggregate/join and cleaning processes.
Data Size
There are many distinct forms and sizes of datasets. This variable determines your choice between ETL and ELT. ELT is utilized for huge datasets so that an enormous amount of data may be handled and converted simultaneously. Large datasets may now be processed as a single unit because of enhancements in processing speed and capability. Typically, the ETL method is associated with smaller data sets.
Cost
In addition to the above, it is essential to evaluate how costly dealing with data might be. Moving the bits that make-up data is one of the costliest operations that can be performed with it. Frequently, the data is already in the destination system, and the request is to cleanse/format/aggregate the data. If you simply have an ETL tool, you must physically transport the data out of the database, into an external system for processing, and back into the database or warehouse. This procedure — relocating all these components — can become prohibitively expensive and labor-intensive. Rather, if the data is already present and “unlimited processing” is accessible on demand in a cloud data warehouse, it may be advantageous to employ the vast parallel processing capabilities that is available to accomplish what is necessary with the data without moving it. This is a far more efficient procedure, with fewer moving elements to coordinate.
Data source
The source of the data is also relevant here. Which application or data source does it originate from? Does this source simply relate to what your firm employs, or will a large deal of data transformation be required to make it usable? Is it originating from a physical location or the cloud? In addition, the ELT strategy will utilize set-wise operations on the data, which are intrinsically quite “batch-y.” This may be acceptable – and well-suited – for bigger amounts of data, but it is not suitable for data that is more comparable to streaming or messaging. In this instance, ETL will always be the superior method.
Data destination
Within your business, the question of the data’s destination is closely related to its origin. Does it link readily to the data source? Are they from several manufacturers with minimal connective tissue? Will the data from one product have to be formatted differently for the data warehousing solution to use it? ETL is frequently the chosen approach for data that has a distinct source and destination product or style, or that is held on-premises, whereas ELT is frequently used for data that is being transferred between identical products.
Intensity
This question is subjective, but the goal is to determine how much effort the data transformation will require to be usable for your team’s analytical and decision-making needs. In this case, size is also significant. If the process of transformation is less complicated, ELT may be the best option. If the transformations are complicated, many businesses choose ETL so that just a portion of the work is performed at a time rather than all at once. Having additional resources available to process larger datasets through ELT may no longer be a concern with the power of cloud solutions allowing you to grow your capabilities and scale as needed.
As you guessed, data transformation occurs in several locations based on the approach you select. Before the data reaches the warehouse, there is a step in ETL where transformations are performed.
In ELT, the data transformation is performed by the data warehouse or database management system into which the data has been imported. ELT requires only the raw data from the database to function but requires significantly more processing power and overhead to store and convert the data. This, in turn, allows for a shorter period between data extraction and use, as well as better customization options. Because of this, business teams can now rapidly construct their own data pipelines and receive immediately actionable insights.
How Does the ETL Process Differ from the ELT Process?
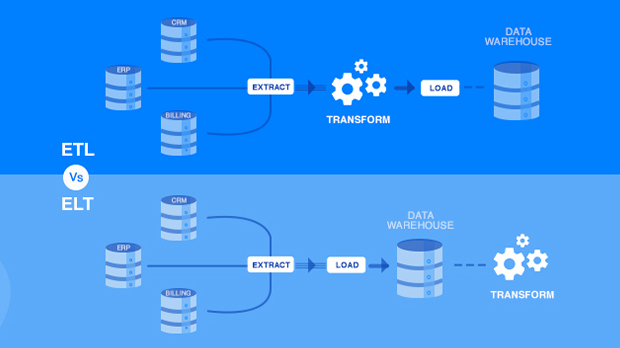
ETL and ELT vary primarily in two ways. One distinction is where data transformation occurs, and the other is how data warehouses store data.
- ELT changes data within the data warehouse itself, whereas ETL transforms data on a separate processing server.
- ELT provides raw data straight to the data warehouse, whereas ETL does not transport raw data into the data warehouse. The process of data intake is slowed down for ETL by converting data on a separate server prior to loading.
In contrast, ELT provides quicker data intake since data are not transmitted to a separate server for reorganization. Using ELT, data may be concurrently imported and converted.
ELT’s preservation of raw data generates a rich historical archive to produce business information. As objectives and tactics evolve, BI teams may re-query raw data to create new transformations based on exhaustive datasets. In contrast, ETL does not provide comprehensive raw data sets that may be repeatedly queried.
These qualities make ELT more adaptable, efficient, and scalable, particularly for ingesting huge quantities of data, processing data sets containing both structured and unstructured data, and creating different business intelligence. In contrast, ETL is appropriate for compute-intensive transformations, systems with outdated architectures, and data operations that require alteration prior to entering the destination system, such as the removal of personally identifiable information (PII).
ETL vs ELT: 12 Key Differences
| Criteria | ETL | ELT |
| Availability of experts | ETL technology has been around for many decades, and resources are readily available | ELT is a new paradigm of doing things. Finding an expert to build your ELT pipeline may vary from easy to very difficult, depending on the use case. |
| Handling of raw data | Raw data gets transformed before loading into the data warehouse | Raw data gets loaded as is to the data warehouse |
| Handling of transformations | Transformations are handled in a staging server before data is loaded into the data warehouse. | Transformations can be applied on the fly using SQL views Transformations can also be applied using MapReduce and other technologies. |
| Support for data lakes | ETL does not lend itself well to data lake use cases | In the ELT approach, data is typically loaded to object storage which acts as the data lake. This data is processed downstream based on the use case to be tackled. |
| Compliance | In an ideal world, all sensitive data should be redacted before leaving the production environment. When that happens, both ETL and ELT strategies end up with the same security posture. However, in most cases, source systems may not have native data masking and redaction capabilities. In such cases, having a transformation engine with limited access to sensitive data offers greater compliance and unauthorized access. | When source data cannot be masked, ELT approaches pose challenges downstream as sensitive data is replicated to the destination only to be masked and transformed later. Therefore, stringent security measures are necessary to ensure compliance requirements are met, and data is not compromised. |
| Data size considerations | ETL is suited for data sizes varying from a few GB to a few TB | ELT is often a better architecture pattern for large data sets |
| Supported Data warehouses | ETL has been around a long time. ETL techniques can be applied to both legacy on-premises data warehouses as well as modern cloud data warehouses. | ELT is a new paradigm that works with cloud-based data warehouses like Snowflake, Bigquery, Redshift and others. Although Oracle’s Data Integrator product has supported ELTs for many years now, the adoption of this strategy has blossomed after cloud technologies came to the forefront. |
| Hardware requirements | Most ETL solutions today are cloud-based. However, they require the installation of software in a cloud VM. | Modern ETL tools are cloud-based and require no additional hardware. |
| Maintenance | Cloud-based ETL or data pipeline solutions, like Daton, require zero maintenance. Legacy ETL tools that run on-premises do require some upkeep. | Modern ETL tools are cloud-based and require no additional hardware. |
| Staging area | A staging area is required for an ETL process to function | No staging area is needed for an ELT process to function |
| Costs | Cloud-based ETL or data pipeline solutions, like Daton, start at $20. Usage-based pricing is a standard strategy for these tools. | Cloud-based ELT or data pipeline solutions, like Daton, start at $20. Usage-based pricing is a standard strategy for these tools. |
| Unstructured data support | ETL processes do not provide an elegant solution to handle unstructured data | ELT is the perfect strategy to handle unstructured data. Downstream transformation routines can support various use cases based on the raw data in the data lake |
| Data processing time | ETL processes take a longer time to run before data is loaded in the warehouse. | Since the transformation happens after the loading processes are complete, data is available in the warehouse sooner. |
Which is Superior: ETL vs ELT?
| Concept | ETL | ELT |
| Business logic (hosted in) | Transformation layer | Target data store |
| Volume | Low to medium | Low to large |
| Speed | Slow | Fast |
| Variety | Can support any type of data asset | Can support any type of data asset |
Cloud data warehouses have spawned a new frontier in data integration, but the choice between ETL vs ELT relies on the requirements of the team. Although ELT offers exciting new benefits, some teams may continue to utilize ETL if the approach makes sense for their deployment, regardless of whether they have an existing infrastructure. Regardless of the option, data teams across the board are achieving success by leveraging a data integration platform to implement their integration objectives.
Conclusion
ETL and ELT are two distinct procedures used to achieve the same criteria, namely preparing data for analysis and use in corporate decision-making. ELT process implementation is more complicated than ETL, although it is now favored. ELT design and implementation may need more effort, but the long-term advantages are greater. ELT is often a cost-effective approach since it involves fewer resources and less time. However, if the destination system is insufficiently strong for ELT, ETL may be a preferable alternative.
Daton’s automated ELT platform provides a cloud-based, visual, and no-code interface making data replication and transformation a breeze. Daton’s 100+ pre-built data connectors eliminate the burden of data engineering and simplify the life of analysts and developers alike. By making data available in the data warehouse in just a few clicks, Daton, the eCommerce-focused data pipeline empowers analysts to focus their efforts on finding insights and contributing to business growth rather than on building the data pipeline.